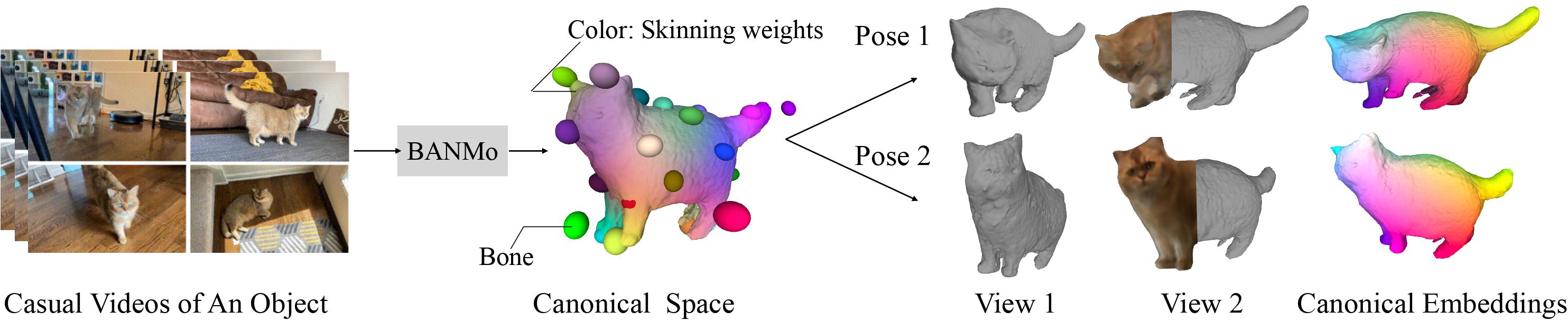
Given multiple casual videos capturing a deformable object,
BANMo reconstructs an animatable 3D model, including an implicit canonical 3D shape, appearance,
skinning weights, and time-varying articulations, without pre-defined shape templates or registered cameras.
Left: Input videos; Middle: 3D shape, bones, and skinning weights (visualized as surface colors) in the canonical space;
Right: Posed reconstruction at each time instance with color and canonical embeddings (correspondences are shown as the same colors).
Left: Input videos;
Right: Reconstruction at each time instance. Correspondences are shown as the same colors.
Abstract
Prior work for articulated 3D shape reconstruction often relies on specialized sensors (e.g., synchronized multi-camera systems),
or pre-built 3D deformable models (e.g., SMAL or SMPL).
Such methods are not able to scale to diverse sets of objects in the wild.
We present BANMo, a method that requires neither a specialized sensor nor a pre-defined template shape.
BANMo builds high-fidelity, articulated 3D models (including shape and animatable skinning weights)
from many monocular casual videos in a differentiable rendering framework.
While the use of many videos provides more coverage of camera views and object articulations,
they introduce significant challenges in establishing correspondence across scenes with different backgrounds,
illumination conditions, etc. Our key insight is to merge three schools of thought;
(1) classic deformable shape models that make use of articulated bones and blend skinning,
(2) volumetric neural radiance fields (NeRFs) that are amenable to gradient-based optimization, and
(3) canonical embeddings that generate correspondences between pixels and an articulated model.
We introduce neural blend skinning models that allow for differentiable and invertible articulated deformations.
When combined with canonical embeddings, such models allow us to establish dense correspondences across videos
that can be self-supervised with cycle consistency. On real and synthetic datasets,
BANMo shows higher-fidelity 3D reconstructions than prior works for humans and animals,
with the ability to render realistic images from novel viewpoints and poses.
Casual-cat-0. Top left: reference image overlayed with input densepose features. Top middle: reconstructed 1st frame shape. Top right: recovered articulations in the canoincal space. Bottom row: reconstruction from front/side/top viewpoints. Correspondences are shown as the same color.
Dog(Shiba)-Haru-5. Top left: reference image overlayed with input densepose features. Top middle: reconstructed 1st frame shape. Top right: recovered articulations in the canoincal space. Bottom row: reconstruction from front/side/top viewpoints. Correspondences are shown as the same color.
We inject different levels
of Gaussian noise into the initial root poses, leading to average
rotation errors of {20, 50, 90}°. BANMo recovers a reasonable shape
and refines the root pose even at 90° rotation error.
Novel view synthesis
We render the body motion of cat-pikachiu-05 (left) from a the camera trajectory
of cat-pikachiu-00.
Motion retargeting
After optimizing the model over source videos (haru the shiba inu),
we can re-target to a driving video (pikachiu the cat).
Adaptation to a new video
After optimizing the model over videos of cat-coco,
we adapt it to a single video of cat-socks by fine-tuning.
Visualization of body pose code
After optimizing the model over videos (left), we project the 128-dimensional
body pose code that controls the canonical space body motion (center)
into 2D with PCA and visualize them as colored dots (right).
Bibtex
@inproceedings{yang2022banmo,
title={BANMo: Building Animatable 3D Neural Models from Many Casual Videos},
author={Yang, Gengshan
and Vo, Minh
and Neverova, Natalia
and Ramanan, Deva
and Vedaldi, Andrea
and Joo, Hanbyul},
booktitle = {CVPR},
year={2022}
}
Work is done during Meta AI internship.
Gengshan Yang is supported by the Qualcomm Innovation Fellowship.
Thanks to Shubham Tulsiani, Jason Zhang, and Ignacio Rocco for helpful feedback and discussions,
and Vasil Khalidov for help settting up DensePose-CSE color visualization.
Thanks pet friends pikachiu, tetres,
haru ,
coco and socks
for serving as our models.